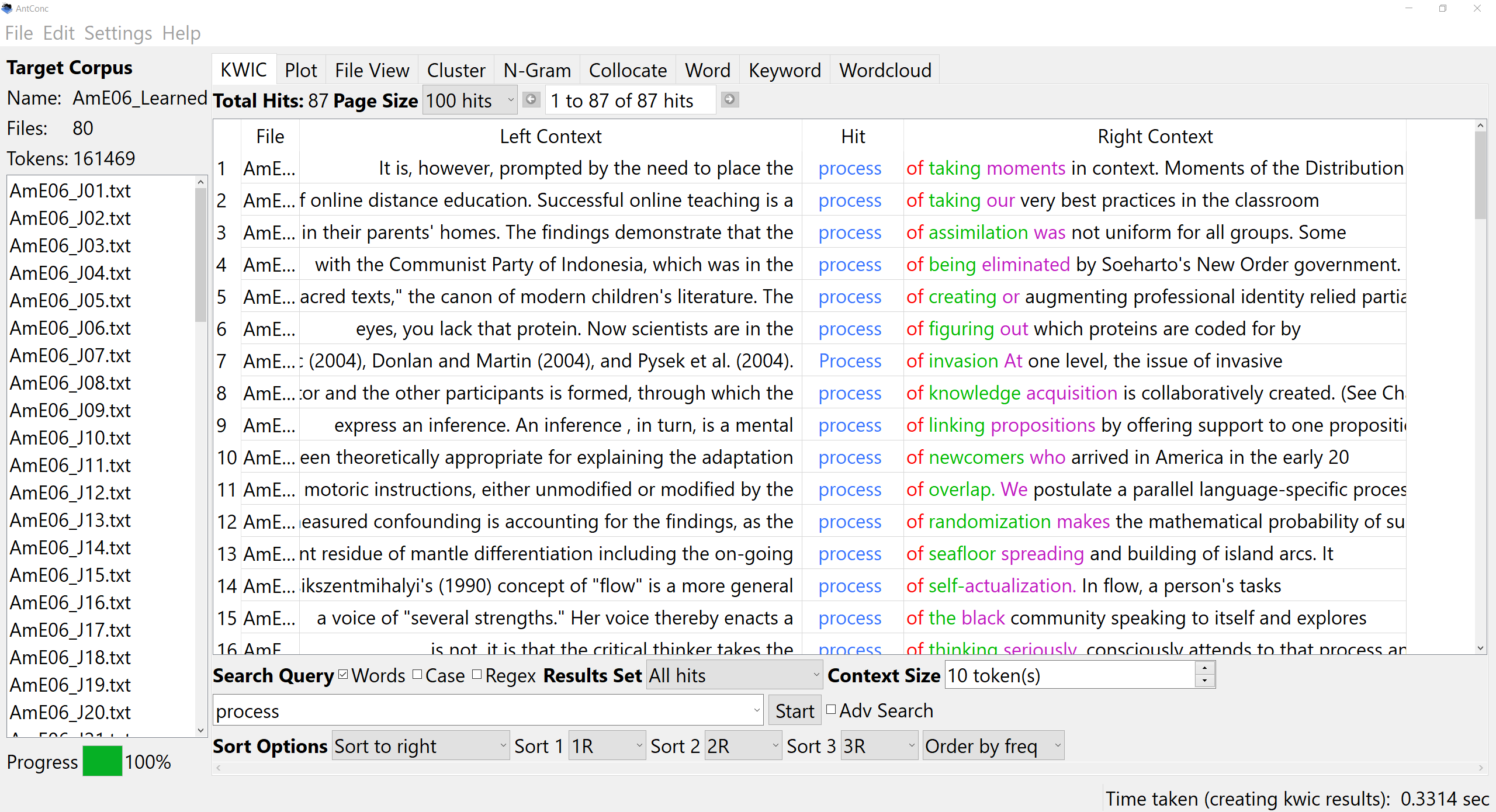
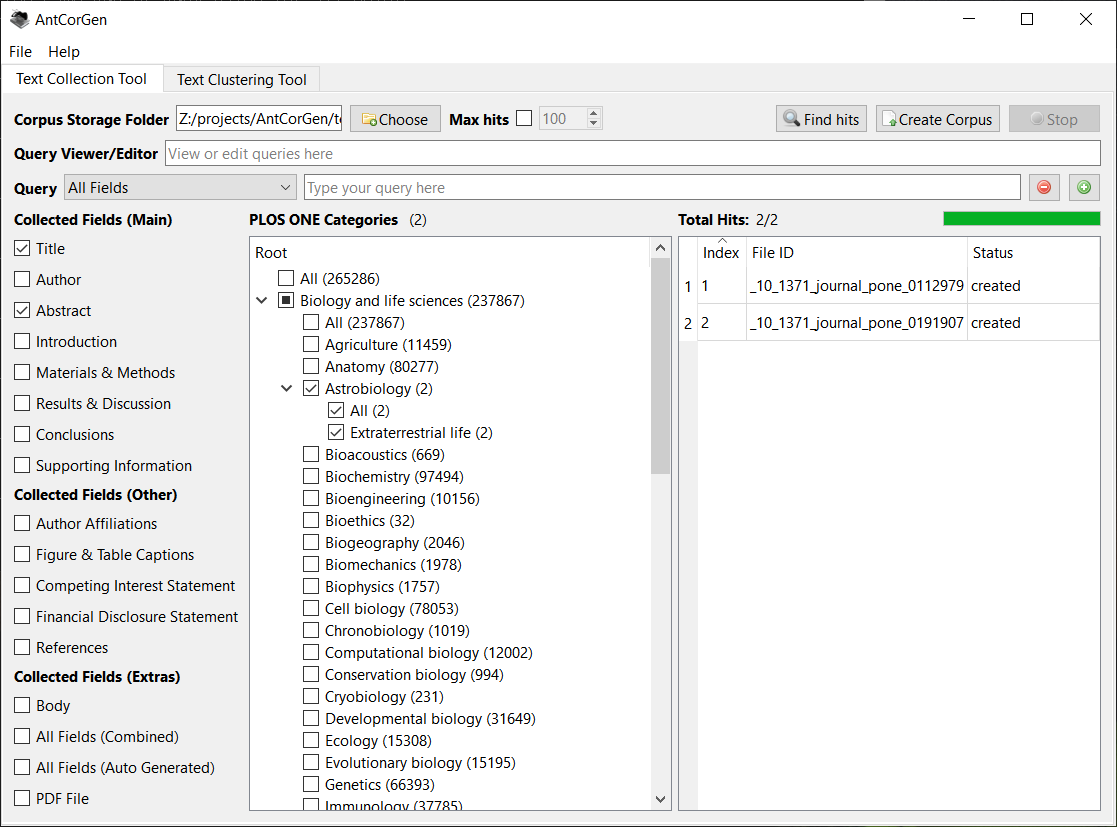
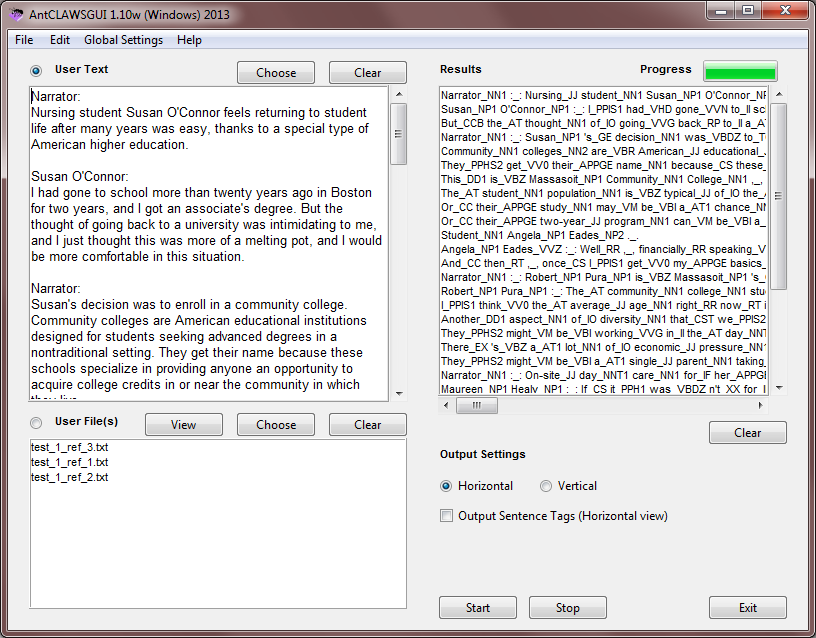
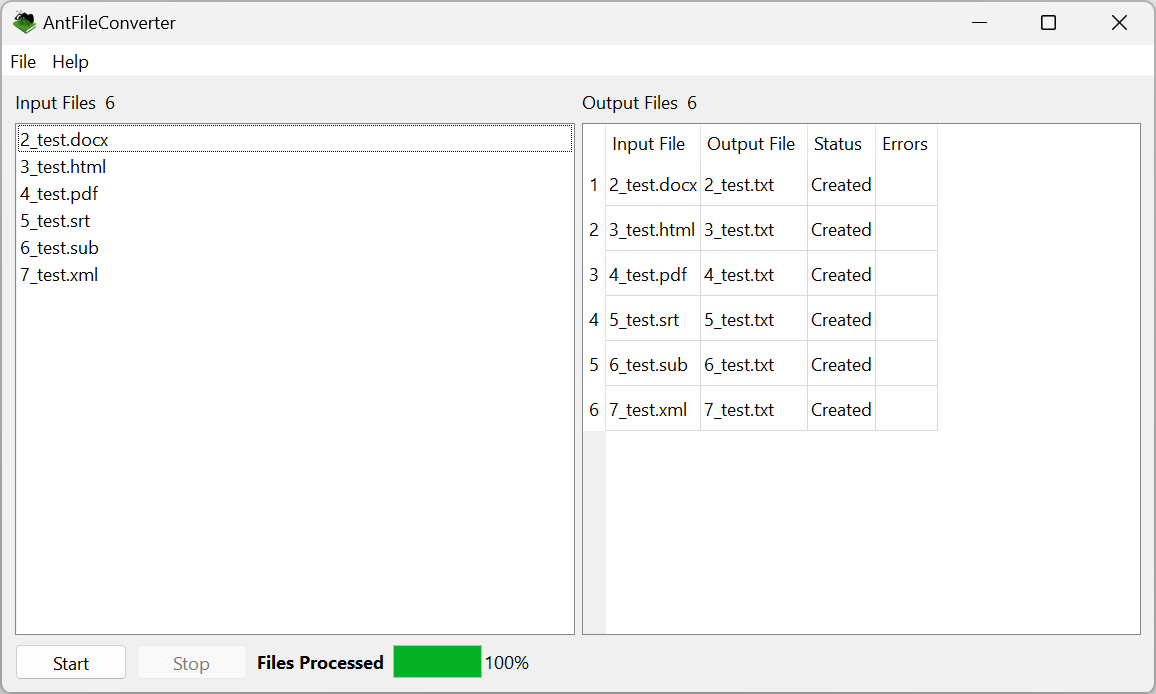
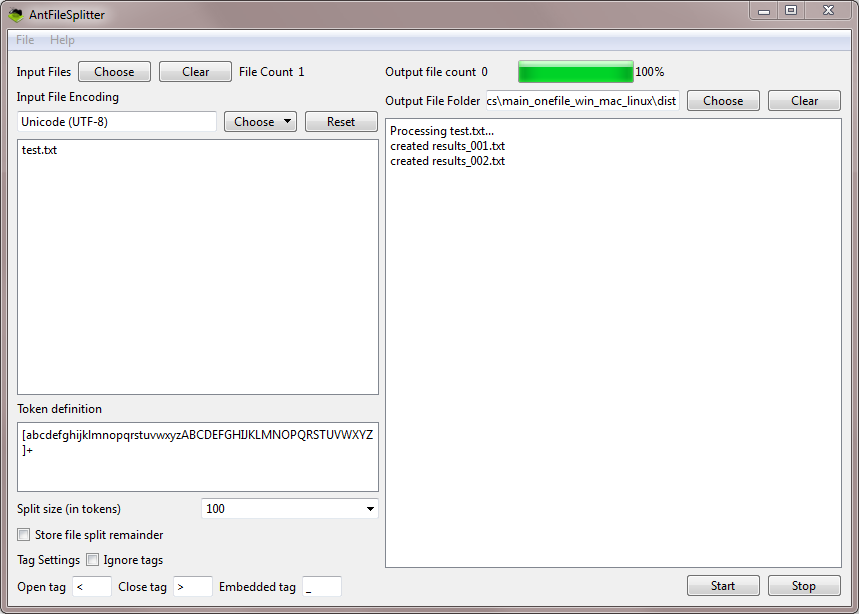
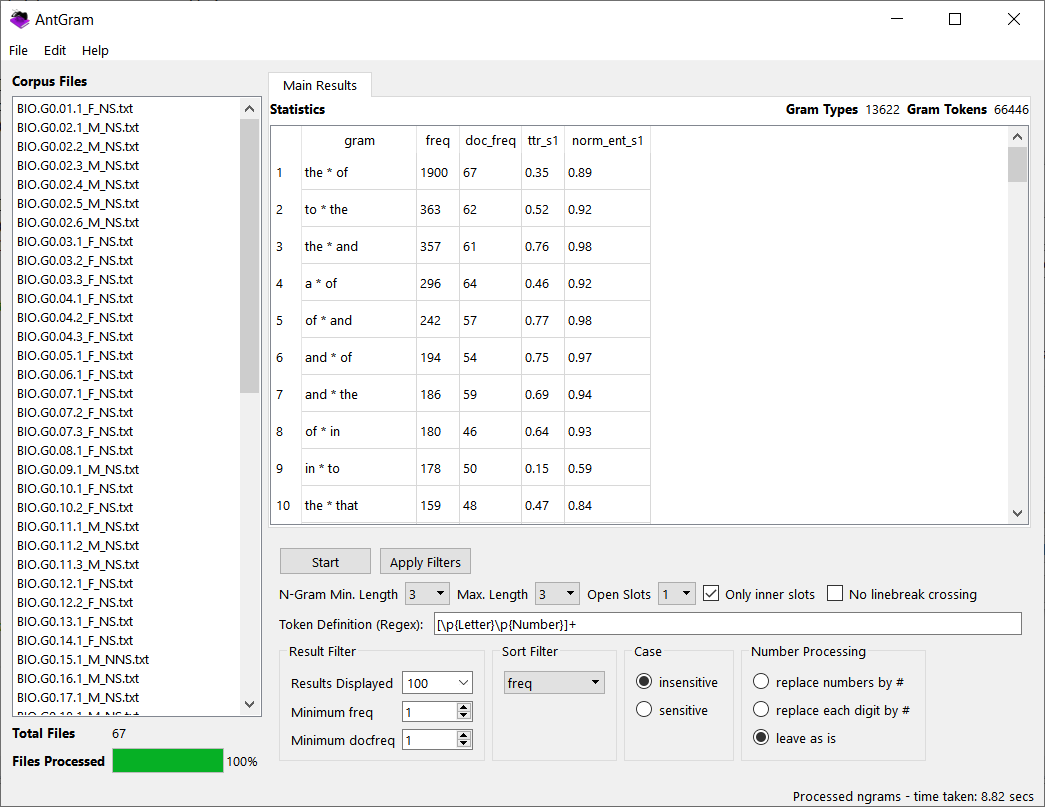
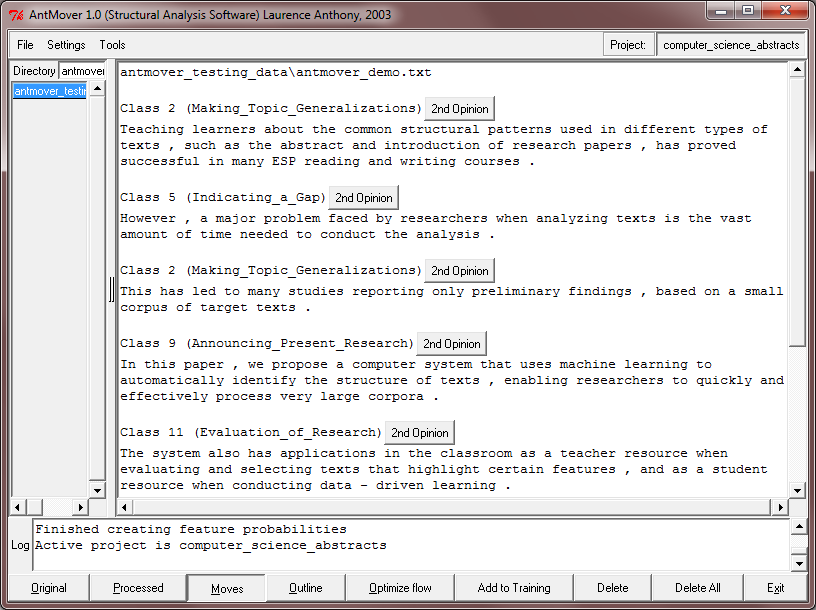
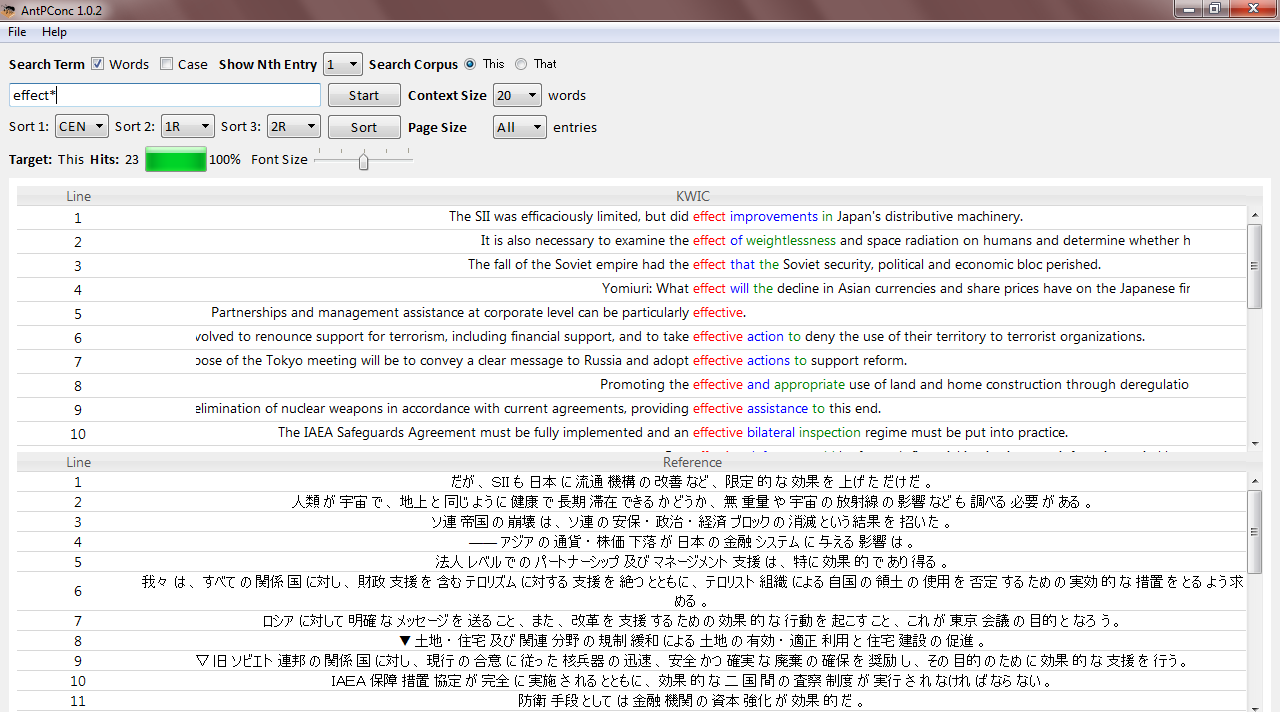
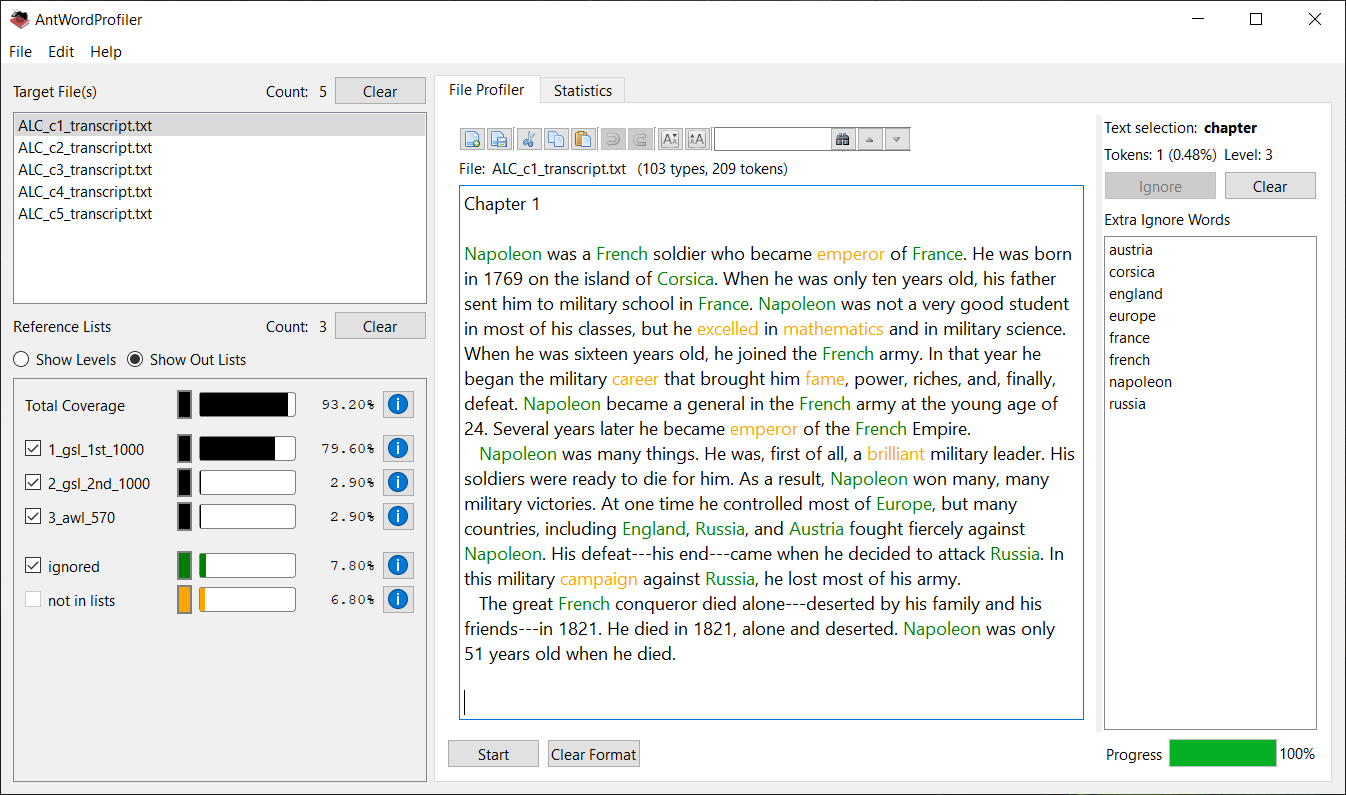
A freeware n-gram and p-frame (open-slot n-gram) generation tool. The functionality of this tool has now been added to AntConc including improvements. I recommend you use AntConc for future work.
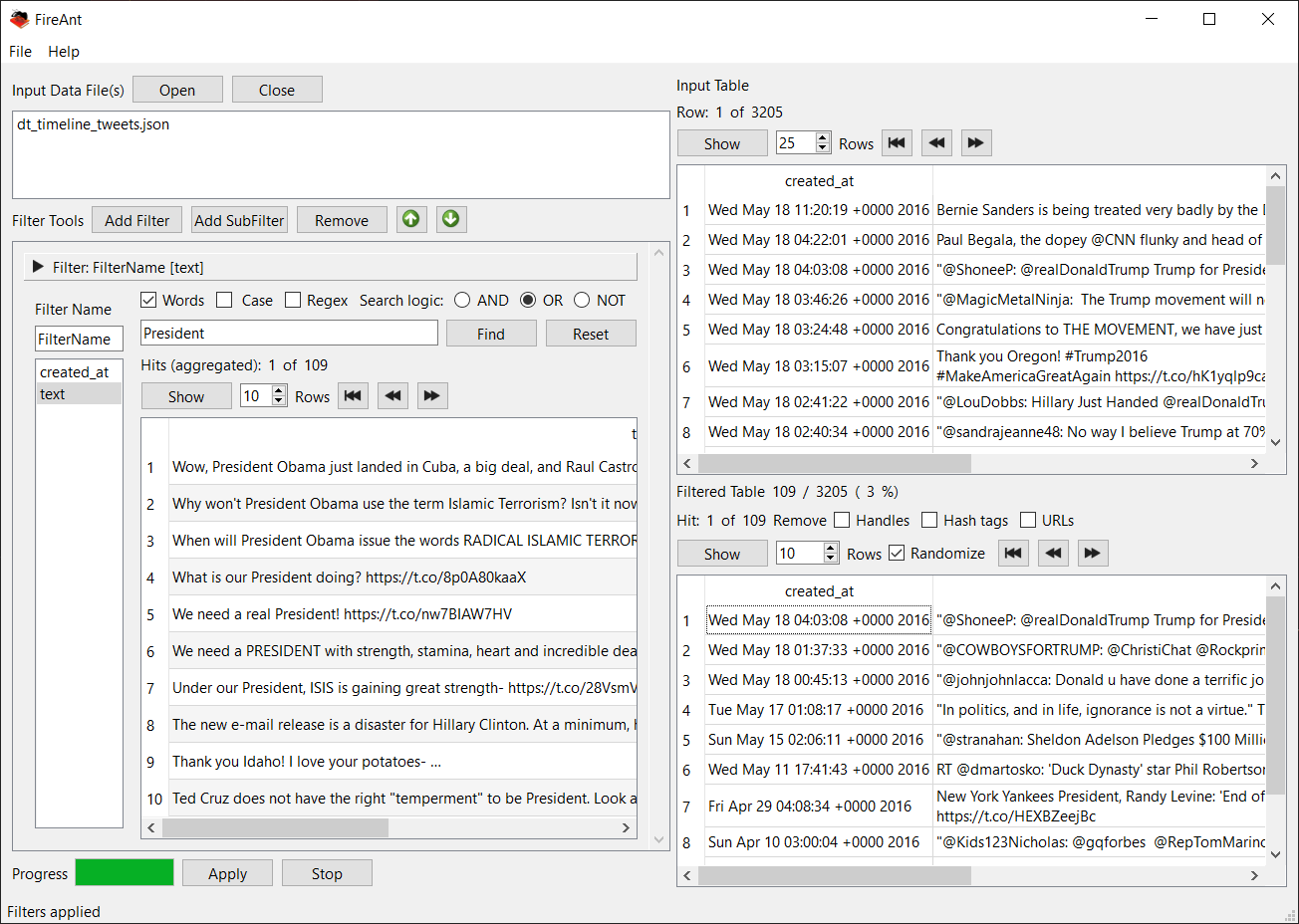
FireAnt (Filter, Identify, Report, and Export Analysis Toolkit) is a freeware social media and data analysis toolkit with built-in visualization tools including time-series, geo-position (map), and network (graph) plotting. Note that Twitter data collection is not currently available due to recent changes in Twitter policies.
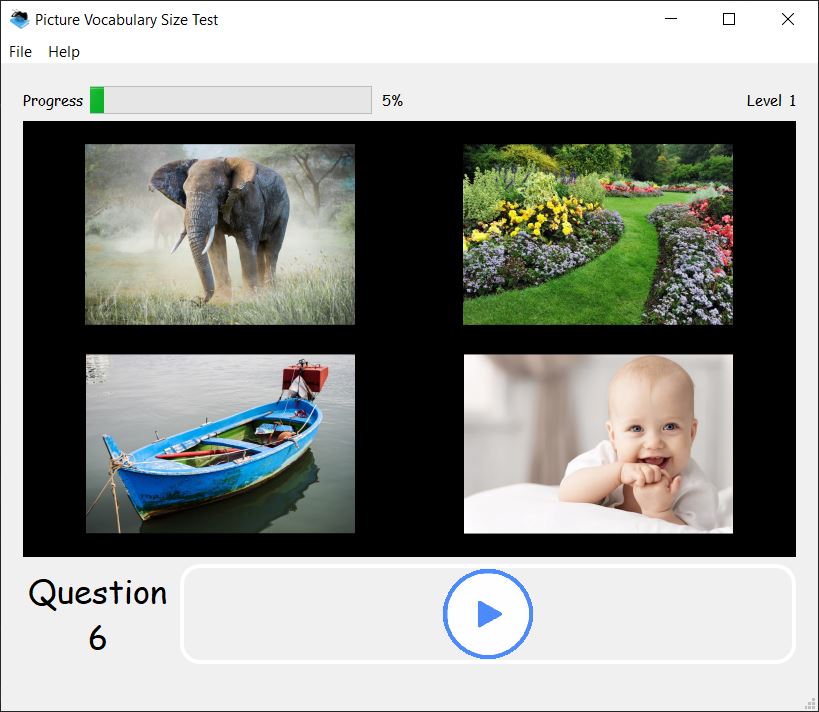
A receptive vocabulary size test using picture choices and oral and written cues designed for pre-literate or l.iterate native speakers and non-native speakers of English. The 20,000 level version can be used with native-speakers of any age. The test was created in collaboration with Paul Nation of Victoria University of Wellington, New Zealand. Remember to download BOTH the main program and one or more test sets. A web-based version (PVST-Web) is also available.
A freeware Japanese and Chinese segmenter (segmentation/tokenizing) tool. The functionality of this tool has now been added to TagAnt including improvements. I recommend you use TagAnt for future work.
A (commercial) learning environment for teaching grammar and vocabulary to EFL learners in Japan. The CASEC G/GTS engine was develop by Laurence ANTHONY (Waseda University, Japan) in collaboration with the Japan Institute for Educational Measurement (JIEM), Tokyo, Japan.
A web-based interface to the ENEJE (English Native Edited Japanese Essays) Parallel Corpus. The ENEJE Parallel Corpus is developed by Laurence ANTHONY (Waseda University, Japan) in collaboration with Nozomi MIKI (Komazawa University, Japan).
A web-based interface to the EXEMPRAES (Exemplary Empirical Research Articles in English and Spanish) Corpus. The EXEMPRAES corpus is developed by Laurence ANTHONY (Waseda University, Japan) in collaboration with Ana Moreno (University of Leon, Spain). Registration is solely intended to monitor the impact of the resource until the complete database is developed.
A web-based interface to the Japanese-English News Articles database of the National Institute of Information and Communications Technology (NICT). WebParaNews is developed in collaboration with Kiyomi CHUJO (Nihon University, Japan).
A freeware, parallel concordancer that allows users to check word and phrase usage in an English and Japanese educational corpus. WebSCoRE is developed by Laurence ANTHONY (Waseda University, Japan) in collaboration with Kiyomi CHUJO (Nihon University, Japan).